



























The data team at Urban Airship has a simple objective: to empower our customers to understand the behavior of users within their app, especially as it relates to the success of their messaging campaigns. To power this, our mobile SDK sends “events” that describe user activity to our servers, where we transform, process and count them. We feel we’re doing our jobs if these counts are broken down in ways that allow our customers to achieve that goal of understanding their users.
The types of events that we think about include “user opened the app,” “user closed the app,” “user interacted with a message,” etc. With billions of app users running our SDK, this results in tens of thousands of events to process every second. In my four years at Urban Airship, that’s a lot of events.
The event-oriented approach to data processing is incredibly powerful. This is the “why” of Urban Airship Connect, which exposes the event stream to our customers. No matter how good a job we do with our reports, the most sophisticated customers (and their SVPs) will have problems that require unfiltered, disaggregated user data.
The Timestamp Issue: Background
One of our worries when we built Connect was exposing our customers to the “weird” data that is bound to come up when dealing with a distributed system of billions of tiny computers. The feature of the data most likely to make it seem strange is the “timestamp” — when the event supposedly occurred. We see a lot of events that claim to have happened before Urban Airship was founded, and a non-trivial number that claim to come from the future. One obvious source of this weirdness is untrustworthy device clocks. Clocks on phones and tablets may go bad or be set improperly. But how much of the skew is due to this?
Consider: sometimes when a user opens an app, they don’t have an internet connection. To handle this, and to conserve battery, our SDK batches events and delivers these batches when it’s able. This leads to events that claim to have happened last week, last month or even last year.
If we were only worried about those clearly-impossible timestamps, we could record the time that our ingress server receives an event and just use that. When watching a stream of aberrant timestamps printed in our service logs, these are certainly the ones that jump out, and this is a fine solution if the bulk of the not-current timestamps are due to device clocks being wrong.
Reports team lore, of which we lacked any hard evidence at the time, is that while device clocks are not exactly reliable, the bulk of the “old” events genuinely happened closer to when they say they happened than to when our servers received them.
A few causes are believed to contribute to this:
Our SDKs batch events and transmit only occasionally (to conserve battery);
Sometimes a device won't have internet access when it does want to transmit a batch;
Attempts to transmit are only made when the app is in the foreground, which may compound the effects of the first two causes.
Because understanding the contribution of each of these sources of apparent event latency is important for our ability to handle them sanely, we did a detailed investigation into how devices represent and report the times at which events occur. Here I present the results of that deep dive, so that those examining the Connect stream understand the timestamps they find on those events.
First, however, the requisite bit of video!
A Proposal to “Correct” Event Timestamps
Russell Mayhew realized that we should be able to correct for device clock skew by subtracting the event's self-reported time from the time the device says it transmitted the event to calculate how long elapsed between the two. Then we could subtract this duration from the time our ingress service received the event to get a more accurate time.
To facilitate this, we added a “transmit time” field to device events. For ingress observed time, we will simply reverse the time UUID already stored on all events. An additional method combines all three fields into a corrected time. This “corrected” time is what you will find as the “occurred” time on events coming through Connect from devices, such as open events. The question remained: how much of a difference in observed latency would this correction make?
OK, But Does it Work?
Here's a weird thing we noticed: about 10% of the time, the device reports that it transmitted the event before the event happened. In such cases, the correction logic simply doesn't work; the library utilities mentioned above in this case will declare no-confidence in the device's clock and fall back to ingress server observed time.
The best explanation we had was that:
An event occurs, a timestamp X is saved
Then, NTP or a cell tower sets the device clock back Y milliseconds
Less than Y milliseconds after X, the event is transmitted
But 10% seemed way too often for this to happen, so we dug in a bit further, and found:
On Android:
This problem doesn't really exist. Transmission time is after event time 99.998% of the time.
On iOS:
Transmission time is after event time only about 86% of the time
Transmission time is before event time by less than one second about 14% of the time
Transmission time is more than one second before event time about 0.002% of the time, comparable to all mis-ordered events on Android
So either iOS itself is doing something weird, or some version(s) of our SDK on iOS are, let’s say, rounding in an odd way. This lead to a long back-and-forth with our mobile client team, with them generating theories and us trying to verify those from data. Eventually we settled on the explanation that the iOS Time Utilities documentation for the CFAbsoluteTimeGetCurrent method is serious when it says, “Repeated calls to this function do not guarantee monotonically increasing results.” In practice, we learned not to rely on sub-second precision of iOS timestamps.
Yeah, But Does it Work?
OK, with that change we will believe we can trust the device to measure relative time about 99.998% of the time. But how much more current will this make events? Will correcting for device clock skew make events seem much less latent/futuristic?
For this I think it's best to compare three distributions:
Naive lag: (ingress time – event time)
Flight time: (ingress time – transmission time)
On-device time: (transmission time – event time)
If a device clock is wrong, it will contribute to large values of flight time; batching will contribute to on-device time. Naive lag is the full distribution we've observed and are trying to explain.
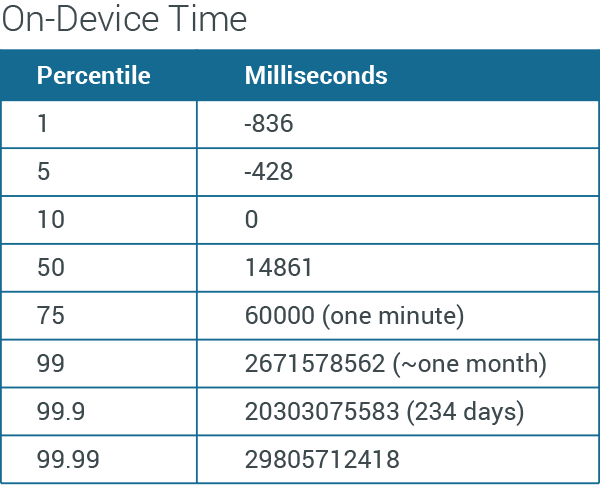
The first thing here is that you see the 10% of events transmitted before they happened, as described above. Seventy-five percent of events are transmitted within a minute of when they believe they occurred, but 1% are sent about a month or more later.
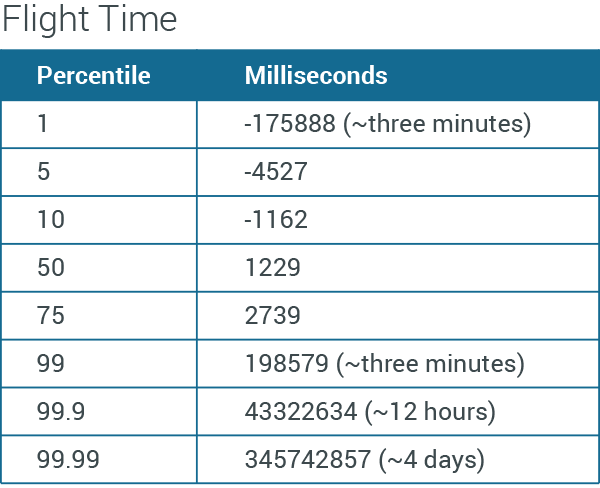
If all clocks were in sync, this would measure how long it takes a device to move over HTTP from a phone to our ingress service. To whatever extent this number is different from positive a couple hundred or a thousand millis, we're looking at either the issue with iOS sending “weird” transmission times, or bad clocks. I think, then, it's safe to say that about 2% of devices have a clock that is three minutes or more off, with that distributed equally between three minutes fast or slow.
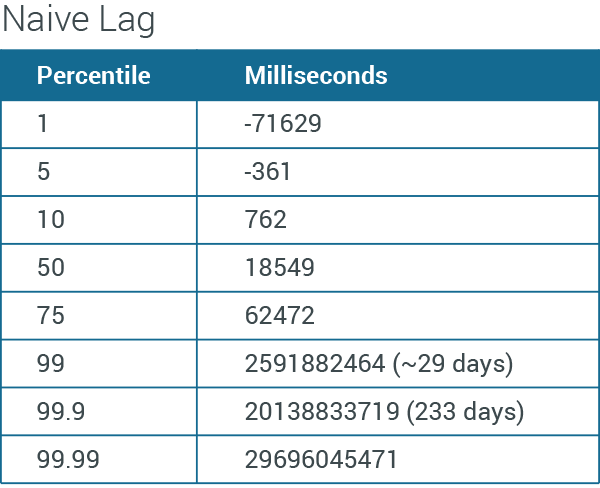
The 1% of devices skewed into the future seem to dominate the low end of this distribution. The rest seems to be dominated by on-device time. To me, this suggests that the bulk of the extent to which event time doesn't match ingress time is due to on-device batching and latency, rather than clock skew.
Wait, You're Saying it Doesn't Work?
It works; it's just not a magic bullet. The clock skew correction seems like a good move: for the 2% of clocks that are off by a few minutes, we get slightly more accurate data, and for the smaller fraction that are way off, we get a big win. But any system dealing with both time and device events will still need to account for the fact that 1% of device events will hang out on-device for a month or longer.
So yes, it can at first be shocking when you see a timestamp that is 100 years in the past, but we try to stay calm and remind ourselves that time traveling computer ghosts don’t exist — and that if they did, they would probably be friendly.
This is just an example of one of the many complex issues that we deal with on a regular basis at Urban Airship since we operate at such massive scale. It won’t be the last. Have thoughts on this issue? We’d love to hear from you.
![The best retail customer engagement platforms for no-code growth teams [2026]](https://www.airship.com/wp-content/uploads/2026/06/The-best-retail-customer-engagement-platforms-for-no-code-growth-teams-2026-404x211.png)
![Retail customer engagement: The ultimate guide to growing your business in 2026 [5 real examples]](https://www.airship.com/wp-content/uploads/2026/06/Retail-customer-engagement-The-ultimate-guide-to-growing-your-business-in-2026-5-real-examples-404x211.png)
